

Often, all researchers see when evaluating the outcome of a study are survey results. Underneath any mean, however, there are genuine responses, as well as those that were made haphazardly, without careful thought. We explain the havoc these satisficers can wreak on your survey results in a previous blog post. The danger, ultimately, is that satisficers in your sample will pull your means in all sorts of directions, leaving you with unreliable data.
The image below shows this process in theory. The red line is the satisficing group and the blue line is the “true” group. The purple dotted line shows the average of the two groups. (Illustrative only, not real data.)
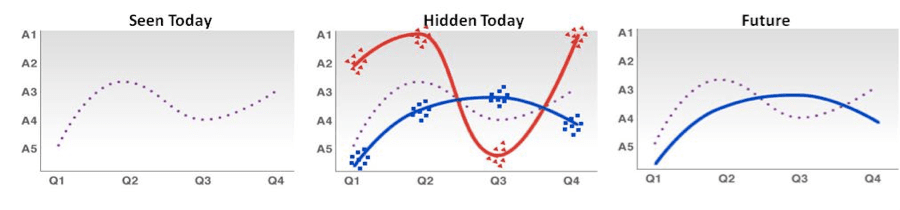
As you can see, satisficers answer very differently from genuine respondents. Leaving their survey responses in your sample may lead to misleading results, which would lead to the wrong conclusions. Therefore, it’s essential to be able to separate the satisficers from genuine respondents. Previous attempts to do this haven’t always been successful. At SurveyMonkey, however, we have developed a procedure to find the satisficers on any survey.
Our satisficing detection procedure depends on a statistical theory called Bayesian inference, with a bit of “machine learning.” Essentially, it will examine a data file to recognize a “normal” pattern of results. The machine-learning portion can either learn from the first portion of observations entered into the database if they are added in real time, or it can analyze an entire set if all data have been collected.
One easy way to understand this is if a person checks the ‘male’ box for gender, but the ‘yes’ box for “have you been pregnant in the past three years,” that would not be an expected response from a respondent carefully filling out the survey. Multiple mismatches in responses across a questionnaire with, say, five questions or more would suggest (though not guarantee) satisficing. The more outlandish the combinations of answers, the more likely the person isn’t who we need in our data-set—especially if we are doing research to understand what most people think, on average.
We’ve tested this procedure to see if it actually can find satisficers, and we’ve found that it does very well. As we are in the finishing stages, we will be able to share more details about the tool and what it will look like later on. For now, let us know what you generally think of this new tool in the comment section.


